The HTTP Archive release cycle
The HTTP Archive dataset is updated each month with data from millions of web pages. This guide explores the end-to-end release cycle from sourcing URLs to publishing results to BigQuery.
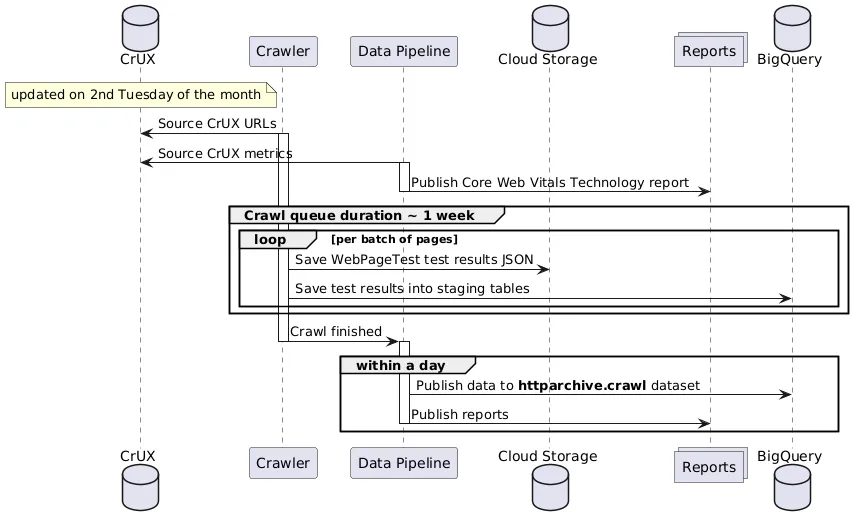
Sourcing URLs
Section titled “Sourcing URLs”The pages HTTP Archive tests are ultimately sourced from the Chrome UX Report (CrUX) dataset. CrUX is a public dataset that contains anonymized, aggregated metrics about real-world Chrome users’ experiences on popular destinations on the web. HTTP Archive takes the origins in the public CrUX dataset and classifies them as either desktop and mobile. Origins are segmented by desktop or mobile depending on the form_factor dimension in the CrUX schema, which corresponds to the actual device type real visitors used to access the website.
CrUX also includes origins without any distinct form factor data. HTTP Archive classifies these origins as both desktop and mobile.
Running the crawl
Section titled “Running the crawl”Previously, HTTP Archive would start testing each web page (the crawl) on the first of the month. Now, to be in closer alignment with the upstream CrUX dataset, HTTP Archive starts testing pages as soon as the CrUX dataset is available on the second Tuesday of each month. Crawl dates are always rounded down to the first of the month, regardless of which day they actually started. For example, the June 2023 crawl kicks off on the 13th of the month, but the dataset would be accessible on BigQuery under the date 2023-06-01.
Publishing the raw data
Section titled “Publishing the raw data”As each page’s test results are completed, the raw data is saved to a public Google Cloud Storage bucket. Once the crawl is complete, the data is processed and published to BigQuery. The httparchive.crawl dataset is available to the public for analysis.
Generating reports
Section titled “Generating reports”The reports on the HTTP Archive website and auxilliary ones like the Core Web Vitals Technology Report are automatically generated as soon as the data is available in BigQuery.